Contents (A) Expected Utility with Univariate Payoffs (A) Expected Utility with Univariate Payoffs The von Neumann-Morgenstern expected utility hypothesis claimed that the utility of a lottery could be written as U = å xÎ supp(p) p(x)u(x) where we referred to U: D (X) as the expected utility function and u: X ® R as the implied elementary utility function. At the risk of confusion with the literature, we shall refer to the utility function on outcomes, u: X ® R, as the elementary utility function (what we sometimes referred to earlier as the "Bernoulli utility function") and reserve the term "von Neumann-Morgenstern utility function" to U(p), the utility of a lottery. After the axiomatization of the expected utility hypothesis by John von Neumann and Oskar Morgenstern (1944), economists began immediately seeing the potential applications of expected utility to economic issues like portfolio choice, insurance, etc. These simple applications tended to use simple models where outcomes were expressed as a single commodity, "wealth", thus the set of outcomes X, became merely the real line, R. As a result, a "lottery" is now conceived as a random variable z taking values in R. Consequently, preferences over lotteries can be thought of as preferences over alternative probability distributions. Thus, letting Fz denote the cumulative probability distribution associated with random variable z where Fz(x) = prob{z £ x}, then we can think of agents making choices over different Fz. Accordingly, the preferences over lotteries, ³ h, are now defined over the space of cumulative distribution functions. Thus, letting the von Neumann-Morgenstern utility function U represent preferences over distributions, then lottery Fz is preferred to Fy, Fz ³ h Fy if and only if U(Fz) ³ U(Fy). Consequently, the expected utility decomposition of U(Fz) is now:
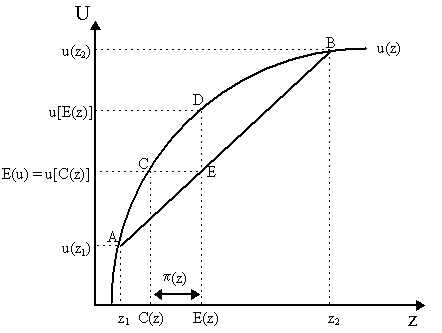
where u: R ® R is the elementary utility function over outcomes. Naturally, if z only takes a finite number of values and thus there were a finite number of probabilities, then this becomes the more familiar U(Fz) = å x p(x)u(x). (B) Risk Aversion, Neutrality and Proclivity We first turn to the concept of univariate "risk aversion" which, intuitively, implies that when facing choices with comparable returns, agents tend chose the less-risky alternative, a construction we owe largely to Milton Friedman and Leonard J. Savage (1948). We can visualize the problem as in Figure 1 below. Let z be a random variable which can take on two values, {z1, z2}, and let p be the probability that z1 happens and (1-p) the probability that z2 happens. Consequently, expected outcome, or E(z) = pz1 + (1-p)z2 which is shown in Figure 1 on the horizontal axis as the convex combination of z1 and z2. Let u: R ® R be the elementary utility function depicted in Figure 1 as concave. Thus, expected utility E(u) = pu(z1) + (1-p)u(z2), as shown in Figure 1 by point E on the chord connecting A = {z1, u(z1)} and B = {z2, u(z2)}. The position of E on the chord depends, of course, on the probabilities p, (1-p).
Notice by comparing points D and E in Figure 1 that the concavity of the elementary utility function implies that the utility of expected income, u[E(z)] is greater than expected utility E(u), i.e. u[pz1 + (1-p)z2] > pu(z1) + (1-p)u(z2). This represents the utility-decreasing aspects of pure risk-bearing. We can think of it this way. Suppose there are two lotteries, one that pays E(z) with certainty and another that pays z1 or z2 with probabilities (p, 1-p) respectively. Reverting to our von Neumann-Morgenstern notation, the utility of the first lottery is U(E(z)) = u(E(z)) as E(z) is received with certainty; the utility of the second lottery is U(z1, z2; p, 1-p) = pu(z1) + (1-p)u(z2). Now, the expected income in both lotteries is the same, yet it is obvious that if an agent is generally averse to risk he would prefer E(z) with certainty than E(z) with uncertainty, i.e. he would choose the first lottery over the second. This is what is captured in Figure 1 as u[E(z)] > E(u). Another way to capture this effect is by finding a "certainty-equivalent" allocation. In other words, consider a third lottery which yields the income C(z) with certainty. As is obvious from Figure 1, the utility of this allocation is equal to the expected utility of the random prospect, i.e. u(C(z)) = E(u). Thus, lottery C(z) with certainty is known as the certainty-equivalent lottery, i.e. the sure-thing lottery which yields the same utility as the random lottery. However, notice that the income C(z) is less than the expected income, C(z) < E(z). Yet we know that an agent would be indifferent between receiving C(z) with certainty and E(z) with uncertainty. This difference, which we denote p (z) = E(z) - C(z) is known as the risk-premium, i.e. the maximum amount of income that an agent is willing to forego in order to obtain an allocation without risk (Pratt, 1964). Turning to generalities, letting u: R ® R be a elementary utility function, z be a random variable with cumulative distribution function Fz, so Fz(x) = P{z £ x}. We denote by M the set of all random variables. For a particular random variable z Î M, the expected z is E(z) = ò R x dFz(x) and the expected utility is E(u(z)) = ò Ru(x) dFz(x). Let Cu(z) denote the certainty-equivalent allocation, i.e. Cu(z) ~h z and the risk premium as p u(z) = E(z) - Cu(z) - where the superscript "u" reminds us that certainty equivalence and risk-premium are dependent on the form of the elementary utility function. Then we can define risk-aversion as follows:
This just formalizes the notion that we had in Figure 1. Of course, we can easily visualize that if an agent is not risk averse, for instance he does not care about risk, then we should expect that receiving E(z) with certainty or uncertainty should not matter to him, thus u(E(z)) = E(u). In terms of Figure 1, this would require that the elementary utility function u(z) be a straight line so that points D and E coincide. It is obvious in this case that Cu(z) = E(z) and p u(z) = 0. Thus:
Finally, if we have a risk-loving agent, we should expect that he would prefer receiving E(z) with uncertainty than receiving it with certainty, thus u(E(z)) < E(u). In this case, his utility function would have to be one where point E lies above point D. This will be the case if the elementary utility function u: R ® R is a convex function. It is easy to visualize that, in such a case, he would pay a premium to take on the risk or, equivalently, one would have to pay him to move to a certainty-equivalent allocation, thus Cu(z) > E(z) and p u(z) < 0. Thus:
Now, we have appealed to the ideas of concave, linear and convex utility functions to represent risk-aversion, risk-neutrality and risk-proclivity. Consequently, let us state the following theorem:
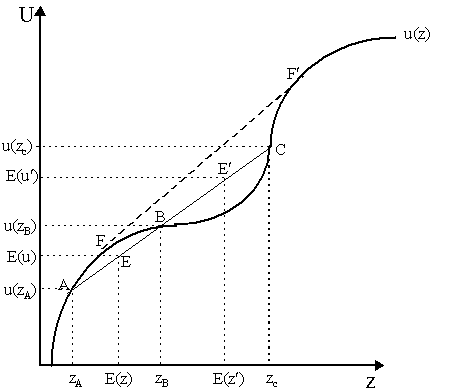
Proof: (i) Let u be concave. Then by definition of concavity u(a x + (1-a )y) ³ a u(x) + (1-a )u(y) for all x, y Î R and a Î (0, 1). But E(z) = a x + (1-a )y and E(u) = a u(x) + (1-a )u(y). Thus, this inequality implies u(E(z)) ³ E(u). As by definition E(u) = u(Cu(z)), then u(E(z)) ³ u(Cu(z)). As u is monotonically increasing, then E(z) ³ Cu(z), which is the definition of risk-aversion. (ii) and (iii) follow analogously.§ Of course, as Milton Friedman and Leonard J. Savage(1948) indicated, it is not necessarily true that an individual's utility function has the same kind of curvature everywhere: there may be levels of wealth, for instance, when he is a risk-lover and levels of wealth when he is risk-neutral. We can see this in the famous Friedman-Savage double inflection utility function in Figure 2. Obviously, u(z) is concave up until inflection point B and then becomes convex until inflection C after which it becomes concave again. Thus, at low income levels (between the origin and zB) agents exhibit risk-averse behavior; similarly, they are also risk averse at very high incomes levels (above zC). However, between the inflection points B and C, agents are risk-loving.
Friedman and Savage (1948) tried to use this to explain why people may take low probability, high-payoff risks (e.g. lottery tickets) while at the same insuring against mild risks with mild payoffs (e.g. flight insurance). To see this, presume one is at point B, on the inflection between risk-aversion and risk-loving. Suppose one faces two lotteries, one yielding A or B another yielding B or C. These lotteries are captured by the solid-line chords between the respective payoffs AB and BC. Expected utility of the first gamble is noted to be E(u) and is depicted in Figure 2 at point E - where, obviously, E(u) is less than the utility of the expected outcome of the first gamble, u(E(z)). Consequently, a risk-averse agent would pay a premium to avoid it. The second gamble yields expected utility E(u¢ ) - at point E¢ on the BC chord - which is greater than the utility of the expected outcome u(E(z¢ )). A risk-loving agent would pay a premium to undertake this gamble. Thus, we can view risk-averse behavior with regard to AB as a case of insurance against small losses and the risk-loving behavior with regard to BC as a case of purchasing lottery tickets. Harry Markowitz (1952), however, disputed the Friedman-Savage conjecture that people, or at least the population in aggregate, have such doubly inflected utility curves. Specifically, Markowitz noted that a person at point F would take also accept a gamble that might take them to F¢ . Conversely, a person at F¢ or slightly below it will not pay a premium against being taken down to F, for instance, i.e. he will not take insurance against situations of huge losses with low probability. Finally, of course, people above F¢ , i.e. the very rich, will never take a fair bet - a phenomenon that does not seem compatible with empirical phenomena such as, well, Monte Carlo casinos. What Markowitz (1952) proposed, instead, was that the z's be considered not "income levels" as Friedman and Savage proposed, but rather "changes in income" and added an additional inflection point at the bottom. People's "normal" income - whether rich, poor or moderate, and controlling for the "utility" derived from the recreational pleasure of gambling - would all be at a point such as B and the rest would reflect deviations from this average income. In this manner, the apparent lottery-insurance paradox is resolved without invoking the strange implications of the original Friedman-Savage hypothesis. (C) Arrow-Pratt Measures of Risk-Aversion How does one measure the "degree" of risk aversion of an agent? Our first instincts may be to appeal immediately to the concavity of the elementary utility functions. However, as utility functions are not unique, second derivatives of utility functions are not unique, and thus will not serve to compare the degrees of risk aversion in any pair of utility functions. However, the risk premiums, expressed in terms of "wealth", might be a better magnitude. If these can be connected then to the "concavity" of utility curves - adjusted to control for non-uniqueness - so much the better. The most famous measures of risk-aversion were introduced by John W. Pratt (1964) and Kenneth J. Arrow (1965). Let u: R ® R and v:R ® R be two elementary utility functions over wealth representing preferences ³ u and ³ v over M respectively. Consider the following definition:
Now consider the following theorem due to J.W. Pratt (1964):
Proof: We shall go (1) Þ (2) Þ (3) Þ (1). (1) Þ (2): First we must establish that T exists. Let v(x) = t. As v is monotonic and continuous, then the inverse v-1 exists and so v-1(t) = x. Thus, u(x) = u(v-1(t)). Let us define T = u° v-1, then u(x) = T(t). But recall that t = v(x), thus u(x) = T(v(x)). Thus T exists. Now, differentiating u¢ (x) = T¢ (v(x))v¢ (x). Thus:
as u¢ (x), v¢ (x) > 0 by assumption of monotonicity. Differentiating again:
or substituting in for T¢ (v(x)):
Thus dividing through by u¢ (x) and rearranging:
Now, by assumption v¢ > 0 and u¢ > 0, thus let v¢ (x)2/u¢ (x) = a > 0 so:
But by (1), v¢ ¢ (x)/v¢ (x) - u¢ ¢ (x)/u¢ (x) ³ 0. Thus, as a > 0, then it must be that -T¢ ¢ (v(x)) ³ 0, or simply, T¢ ¢ (v(x)) £ 0. Thus, for all x Î R, T¢ ³ 0 and T¢ ¢ £ 0, thus T is concave. Q.E.D. (2) Þ (3): Recall that u(Cu(z)) = E(u(z)). Thus, by (2), as u(x) = T(v(x)), then u(Cu(z)) = E(T(u(z))). As T is concave, then by Jensen's inequality:
but as E(T(v(z))) = u(Cu(z)) and E(V(z)) = v(Cv(z)) by definition, then this implies:
or, by (2), as u(·) = T(v(·)), this becomes u(Cu(z)) £ u(Cv(z)). Thus by monotonicity of u, Cu(z)) £ Cv(z) which implies, by definition, that p u(z) ³ p v(z) which is (3). Q.E.D. (3) Þ (1): Let us show, equivalently, that "not (1)" Þ "not (3)". Thus, if "not (1)", then:
By continuity, there is a neighborhood Ne (x° ) for which this is true. Let z be a random variable which takes values only in Ne (x° ), and elsewhere zero. Now, in this area Ne(x° ), T(.) is convex. Why? Well, recall that in our earlier proof of (1) Þ (2), we obtained v¢ ¢ (x)/v¢ (x) -u¢ ¢ (x)/u¢ (x) = -T[v(x)]a . Well, for x Î Ne (x° ), -u¢ ¢ (x)/u¢ (x) < v¢ ¢ (x)/v¢ (x), thus, -T[v(x)]a < 0 for x Î Ne (x° ), thus T¢ ¢ > 0, and thus T(.) is convex. But, by earlier theorem (2) Þ (3), we can see that T¢ ¢ > 0 implies that p v(z) ³ p u(z), i.e. "not (3)". Thus, "not (1)" Þ "not (3)" or, equivalently, (3) Þ (1). Q.E.D. A more direct alternative proof of (3) Þ (1) would be to proceed as follows: Let z = [w - e , 0.5; w + e , 0.5], where w is some initial level of wealth and e is some random variable representing pure risk. Without loss of generality, we assume E(e ) = 0 and thus E(z) = w. Thus, by von Neumann-Morgenstern, E[u(z)] = 0.5[w-e ] + 0.5[w+e ]. By definition of the risk-premium, u(w - p u(z)) = E[u(z)]. Taking a Taylor approximation on the right side (thus we are "scaling" the risk "in the small"):
where o denotes a negligible order of magnitude, i.e. lime ® 0o(e 3)/e 3 = 0. As E[u(w)] = u(w) (as w is certain) and E[u¢ (w)e ] = 0 (as E(e ) = 0) and E[u¢¢(w)e 2] = u¢¢ (w)s 2e (where E(e 2) = s 2e ), then omitting remainders:
Now, taking a Taylor approximation of u(w - p (z)), the left side of our earlier equation, we have:
then equating both sides and omitting remainders:
or:
As s 2 > 0 and faced by all agents, then we can see that if p u(z) ³ p v(z), then -[u¢ ¢ (w)/u¢ (w)] ³ -[v¢ ¢ (w)/v¢ (w)]. Thus, (3) Þ (1). Q.E.D. Thus, (1) Þ (2) Þ (3) Þ (1). § Consequently, we can note that the term -u¢ ¢ (x)/u¢ (x) is another measure of risk-aversion. Thus the term ru(x) = -u¢ ¢ (x)/u¢ (x) is also known as that Arrow-Pratt Measure of Absolute Risk-Aversion or ARA. Notice that ru(x) > 0 if u is monotonically increasing and strictly concave (as in Figure 1 for the risk-averse individual). Naturally, ru(x) = 0 for the risk-neutral individual with a linear utility function and ru(x) < 0 for the risk-loving individual with a strictly convex utility function. As we can see, the Arrow-Pratt measure of absolute risk aversion cannot capture a situation as in Figure 2 as the agent switches from risk-aversion, to risk-loving and then back to risk-aversion. Thus, an alternative would be to weight the measure of risk aversion by the level of wealth, x. In this case we obtain the Arrow-Pratt Measure of Relative Risk-Aversion, or RRA, which is defined as Ru(x) = xru(x) = - xu¢ ¢ (x)/u¢ (x). Of course, even without inflections, increases and decreases in wealth can change the degree of risk-aversion. Specifically, recall that risk-aversion is defined via the risk premium. Thus, let us define the following, where w is wealth, and x is risk where E(x) = 0:
Constant absolute risk aversion (CARA) and increasing absolute risk aversion (IARA) are defined analogously by replacing the appropriate inequalities. Let us now consider the following:
Proof: Let va(w) = u(w+a) and the rest follows by the Pratt theorem. Note that d(-u¢ ¢ (w)/u¢ (w))/dw < 0.§ We can also have changing rates of relative risk aversion. The definition in this case is as follows:
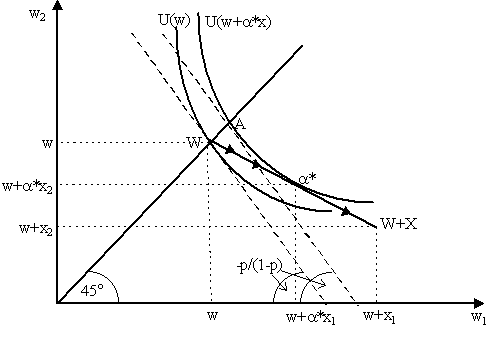
Of course, constant relative risk aversion (CRRA) and increasing relative risk aversion (IRRA) follow analogously. Consider the following famous examples of functions with different degrees of risk-aversion: Example: (DARA/CRRA): u(x) = xa where a Î (0, 1). This displays decreasing absolute risk aversion (DARA) and constant relative risk-aversion (CRRA). To see this, note that u¢ (x) = a xa -1 and u¢ ¢ (x) = a (a -1)xa -2, thus ru(x) = -a (a -1)xa -2/a xa -1 = (1-a )/x ³ 0 so there is absolute risk-aversion. Thus, dru(x)/dx = -(1-a )/x2 < 0 as a < 1, thus we have declining absolute risk aversion. In contrast, Ru(x) = -a (a -1)xxa -2/a xa -1 = 1-a ³ 0, thus dRu(x)/dx = 0, so there is constant relative risk aversion. Notice that the famous CRRA utility function used in macroeconomic consumption theory, u(c) = c1-r /(1-r ) where r Î (0, 1) is merely a special case of this which yields Ru(c) = r , thus r is the "coefficient" of relative risk-aversion. Example: (CARA/IRRA) u(x) = -e-x. This displays constant absolute risk aversion and increasing relative risk aversion. Notice that u¢ (x) = e-x and u¢ ¢ (x) = -e-x. Thus, ru = e-x/e-x = 1 ³ 0. Thus, dru/dx = 0, thus there is constant absolute risk-aversion. Similarly, dRu/dx = x(e-x/e-x) = x, so there is increasing relative risk-aversion. Again, the famous CARA utility function used in macroeconomics, u(c) = -(1/a )e-a c where a > 0 is also a special case of this. Obviously, ru(c) = a , thus a is also known as the coefficient of absolute risk-aversion. Example: Quadratic utility function u(x) = a + b x -g x2 where, for concavity, g > 0. Notice that now we have u¢ (x) = b - 2g x and u¢ ¢ (x) = -2g . Thus ru(x) = 2g /(b -2g x). Notice for ru(x) ³ 0, we need b ³ 2g x, thus it only applies for a limited range of x. Notice that dru(x)/dx ³ 0 up to where x = b /2g . Beyond that, marginal utility is negative - i.e. beyond this level of wealth, utility declines. Notice another implication: namely, that the unwillingness to take risks increases as wealth increases, i.e. that richer people are more unwilling to take risks. Thus, the quadratic utility function exhibits IARA. John Hicks (1962) and Kenneth Arrow (1965) have assaulted the quadratic utility function on this basis. (D) Application: Portfolio Allocation and Arrow's Hypothesis Kenneth J. Arrow (1965) hypothesized that individuals ought to display decreasing absolute risk aversion (DARA) and increasing relative risk aversion (IRRA) with respect to wealth, i.e. dru(x)/dx £ 0 and dRu(x)/dx ³ 0. The reasoning for DARA is, recall, to argue that wealthy individuals are not more risk-averse than poorer ones with regard to the same risk. Thus, as Arrow notes, DARA is necessary if risky assets are to be "normal goods", i.e. a rise in wealth leads to an increase in demand for them - whereas IARA implies they are an inferior good. The reasoning for hypothesizing IRRA is that as wealth increases and the size of the risk increases, then the willingness to accept the risk should decline. Alternatively stated, IRRA implies that the wealth elasticity of demand for risky assets is less than unity. We will verify Arrow's hypothesis in the next section. The basic problem can be set out as a portfolio allocation problem, similar in spirit to Harry Markowitz (1952, 1958) and James Tobin (1958). Let w be initial wealth. Suppose there are two assets: a risk-free asset with zero return and a risky asset whose rate of return (x) is a random variable with positive mean, i.e. E(x) > 0. Thus, letting a Î [0, 1] be the proportion of initial wealth invested in the risky asset, then expected return on a portfolio of size w is E(w + a wx). Obviously, the higher a , the higher the expected return on the portfolio. The portfolio allocation decision is as follows: namely, choose a Î [0, 1] such that the expected utility of the portfolio, E[u(w + a wx)] is maximized. To visualize the problem, we can examine it geometrically in the space of random variables in Figure 3. Suppose the random variable x, the return on the risky asset, takes only two values, x = {x1, x2} where x1 > 0 > x2 where the probability of x1 occurring is p and of x2 is (1-p) and we assume E(x) = px1 + (1-p)x2 > 0. In Figure 3, the horizontal axis measures wealth in state 1 and the vertical axis measures wealth in state 2. Now, initial wealth is w which remains the same regardless of which state occurs. This is shown in Figure 3 by point W which lies on the 45° "certainty line": whether state 1 or state 2 happens, wealth remains w. This is equivalent to the situation where all wealth is held in the form of the riskless asset, i.e. a = 0. If, in contrast, all wealth is held in the form of the risky asset, so a = 1, then the agent receives wealth w + x1 in state 1 and w + x2 in state 2 which is represented as point W+X in Figure 3 which is, of course, off the certainty line. Thus, if 0 < a < 1, then wealth allocation is represented somewhere on the chord between W and W+X, such as at point a * where we have an allocation which yields wealth w+a *x1 in state 1 and w+a *x2 in state 2. Increasing a moves us away from point W and towards point W+X.
Now, expected utility is:
If a = a *, then this is represented by indifference curve U(w+a *x) which passes through a * in Figure 3. If all wealth is held in the form of the riskless asset, a = 0, then E(u) = u(w), which is represented by the U(w) indifference curve passing through W. Totally differentiating, we see that the slope of the indifference curves in Figure 3 are:
Now, when the income in both states are the same, then u¢ 1 = u¢ 2, thus at the 45° line then the slope of the indifference curve is -p/(1-p). This is shown in Figure 3 by the dashed line with slope -p/(1-p) lying tangent to U(w). Notice that the slope of U(w+a *x) is also -p/(1-p) on the 45° line as shown by point A . An agent is thus faced with an indifference curve map on the space of random variables depicted in Figure 3. Maximizing expected utility, then, we can see that the agent will choose a * where the highest isoquant is tangent to the line between W and W+X. This is his optimal allocation of wealth between risky and riskless assets. Notice that the first order condition for a maximum implies:
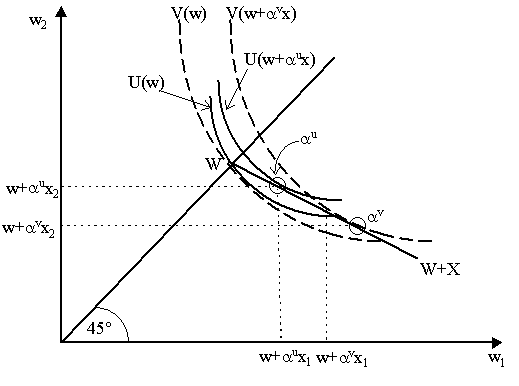
Notice that if the agent places everything in riskless assets so a * = 0, then this implies E[u¢ (w)·wx] = 0 = u¢ (w)wE(x) (as w is certain). But as E(x) > 0 by assumption, then this cannot hold. Thus, by implication, it cannot be that a risk-averting agent will take a completely riskless position, i.e. a * ¹ 0. As long as the returns are actuarially fair, then no matter how risk-averse, an agent will always take some positive amount of the risky asset. How might risk-aversion affect portfolio allocation decisions? Recall that the Arrow-Pratt measure of risk-aversion implies there is a relationship between the degree of concavity of the utility function and the degree of risk-aversion. In the space of random variables, this implies there is a relationship between the degree of convexity of indifference curve and the degree of risk-aversion - with more risk-averse agents having more convex indifference curves. We see this in Figure 4 below where we have two sets of indifference curves - for agent U (solid lines) and agent V (dashed lines). Notice from the (badly drawn) diagram that the indifference curves of agent U are more convex than those of agent V, thus we would argue that U is more risk-averse than V.
Another implication can be immediately drawn from Figure 4. Notice that facing the same portfolio decision, agent V chooses optimal portfolio allocation a v whereas agent U chooses the optimal portfolio allocation a u where, obviously, a u < a v. This seems to arise because of the relative convexity of indifference curves. Does this imply that, in general, the more risk-averse agents will take a smaller proportion of risky assets in their portfolio? Let us see:
Proof: Suppose both agents have the same initial wealth, w. Thus, each agent maximizes E[u(w + a wx)] and E[v(w + a wx)] respectively. For v, the first order condition for a maximum is that:
while the second order condition is:
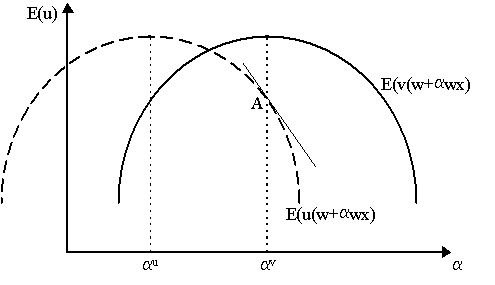
Let a v be the optimal portfolio allocation for agent v. What we are going to do can be illustrated by Figure 5, where we have the expected utility functions of agents u and v over the range of different portfolio allocations, a . Notice that a v yields the maximum expected utility for agent v. Now, suppose agent u is forced to hold agent v's optimal portfolio allocation, a v, then agent u's expected utility will be at point A in Figure 5. If agent u's expected utility is declining at that level, we know that he could improve his expected utility by decreasing the amount of the risky asset he held, i.e. reducing a . Thus, the implication is agent u's optimal portfolio, a u, must have been below agent v's, a v, as we see depicted in Figure 5.
Let us proceed with the proof. Recall from the Pratt theorem that if u is more risk-averse than v, then there is a concave T such that u = T(v). Now, if agent u holds agent v's portfolio, a v, then u has expected utility E[u(w+a vwx)] = E[T(v(w+a vwx))]. Thus, differentiating with respect to a :
Let us now conduct a little plastic surgery. Effectively, we are going to subtract 0 into this equation. Recall, from the first order condition of agent v, E[v¢ (w+a vwx)·wx] = 0. Thus, pre-multiplying this by T¢ (v(w)) implies that still E[T¢ (v(w))·v¢ (w+a v)·wx] = 0 (we can place it within the expectations operator because T¢ (v(w)) is not random). Thus, let us subtract this from the term in the above equation for agent u:
where, because it has value zero, implies there is no change. But then combining terms we obtain:
Now examine this closely: if x > 0, then w + a vwx > w, which implies that v(w+a vwx) > v(w), which implies, in turn that T¢ (v(w+a vwx) < T¢ (v(w)) by the concavity of T. Thus, {T¢ (v(w+a vwx) - T¢ (v(w))} > 0 and so the entire term is negative, i.e. ¶ 2E[·]/¶ a |a =a v. In other words, as shown in Figure 5. the slope of agent u's expected utility at a = a v is negative, thus agent u's expected utility E[u(w + a vwx)] is decreasing if he is forced to hold agent v's optimal portfolio allocation. If so, then the implication is that his own optimal allocation was below agent u's optimal portfolio allocation, i.e. a u £ a v. Thus, the more risk-averse agent holds a smaller proportion of his wealth in the risky asset.§ Let us now turn to verifying Arrow's (1965) hypothesis, namely that if we have decreasing absolute risk aversion (DARA) and increasing relative risk aversion (IRRA) with respect to wealth, then optimal holdings of risky assets increase with wealth but the proportion of wealth invested in assets declines.
Proof: Recall that the agent maximizes E[u(w+a wx)]. Thus, the first order condition is that ¶ E[·]/¶ a = E[u¢ (w+a wx)·wx] = 0 while the second order condition is ¶ 2E[·]/¶ a 2 = E[u¢ ¢ (w+a wx)·w2x2] £ 0. Let a * be the solution to this problem. Letting FOC denote "first order condition" and SOC denote "second order condition", then we know that totally differentiating the FOC:
but as dFOC/da * = SOC, then this reduces simply to:
As we know, SOC £ 0. What about the numerator? Now, dFOC/dw = E[u¢ ¢ (w+a *wx)·wx(1+a *x)] + E[u¢ (w+a wx)·wx]. The second term falls out because of the first order condition, thus we know that the sign of da */dw will be the same as the sign of E[u¢ ¢ (w+a *wx)·wx(1+a *x)]. Let w0 = w(1+a *x), then:
thus:
Now, multiplying and dividing E[u¢ ¢ (w0)·xw0] by u¢ (w0):
Now, let us conduct some more plastic surgery. Recall that the FOC states that E[u¢ (w+a wx)·wx] = E[u¢ (w0)·wx] = 0. Thus, multiplying by the constant u¢ ¢ (w)/u¢ (w), then the FOC says that E[[u¢ ¢ (w)/u¢ (w)]u¢ (w0)·wx] = 0. Thus, subtracting this from our equation above:
which does not make a difference because the subtracted term has value zero. Thus rearranging:
Note that the term [u¢ ¢ (w0)/u¢ (w0)]·w0 is effectively the (negative of) the rate of relative risk aversion for w0 = (1+a *x)w while term [u¢ ¢ (w)/u¢ (w)]·w is effectively the (negative of ) the rate of relative risk aversion for w. Thus, if x > 0, w0 > w. Consequently, by Arrow's hypothesis of increasing relative risk aversion (IRRA), we should expect [u¢ ¢ (w0)/u¢ (w0)]·w0 < [u¢ ¢ (w)/u¢ (w)]·w. Or, in other words, and recalling that x > 0:
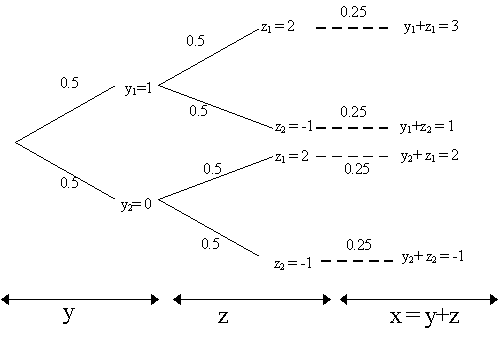
If we now let x < 0, then w0 < w, so the same logic works itself backwards so we know have [u¢ ¢ (w0)/u¢ (w0)]·w0 > [u¢ ¢ (w)/u¢ (w)]·w but as x < 0, then we obtain the same result that the whole term is negative. As a result, as sgn E[u¢ ¢ (w0)·xw0] = sgn da */dw, then da */dw < 0. Thus, as wealth increases, the proportion of wealth held in risky assets declines - which is exactly Arrow's hypothesis. For the rest of the hypothesis, i.e. DARA, let us proceed as follows. Let w1 < w2 and define u1(z) = u(w1 + z) and u2(z) = u(w2 + z). Thus, by DARA, then u1(·) is a concave transformation of u2(·). As a result, we can think of u1(·) as the elementary utility function of a more risk-averse agent and u2(·) as that of a less risk-averse agent. By our previous theorem, we saw that a more risk-averse agent will invest a smaller absolute amount in the risky asset than the less-risk averse. Thus, u1 will invest less than u2, but as w2 > w1, this implies that the amount invested in risky assets increases as wealth increases. Thus, both of Arrow's hypotheses are confirmed.§ (E) Ross's Stronger Risk Aversion Measurement The implicit assumption in the previous section on portfolio allocation was the existence of a riskless asset. Suppose now that we have two risky assets and no riskless asset. Let a be the proportion of wealth held in the form of the riskier asset and thus (1-a ) is the proportion of wealth held in the form of the less risky (but not riskless) asset. Do we still obtain the conclusion that if u is more risk-averse than v that a u £ a v. Stephen A. Ross (1981) has demonstrated that this is no longer true. To see this, consider his example: Ross's Counterexample: Let there be two assets, x and y. Let y pay 1 or 0 with equal probability, i.e. 0.5 each. In contrast, x is much riskier: it pays 3, 2, 0 or -1, each with probability of 0.25 each. Now, we can decompose x into a combination of y and another random variable z. Specifically, letting z = x - y, then x = y + z. Thus, we can think of x being "riskier" than y by taking the payoffs of y and adding another stochastic component z to the already risky payoffs of y. In order for this to be true, then z has to pay 2 or -1 with probability 0.5 each and E(z|y) > 0. We can visualize this decomposition of x heuristically in Figure 6 below where, note, the compound lottery y+z is x. Thus, x is merely y's payoffs plus some more "noise" by z - this is what we mean by x being "riskier" than y (see our section on the definition of "riskiness").
Let a be the proportion of wealth w invested in asset x and (1-a ) the proportion invested in asset y, so w0 = w(a x + (1-a )y) = w(y + a (x-y)) or, normalizing w = 1, then w0 = y + a (x-y). As z = x-y, then w0 = y + a z, thus we need only consider two random variables y and z. We are assuming that z and y are stochastically independent. Notice that when a = 1, then the final compounded terms y + a z are merely x. If a = 0, then we are reduced merely to y. Now, expected utility for the less risk-averse agent v is E[v(a x + (1-a )y)] = E[v(y + a z)], thus differentiating with respect to a , we obtain the first-order condition for a maximum for agent v:
or, substituting our numbers:
Assume that v is such that optimally, a v = 0.25, then:
and assume, for the sake of argument, that v is such that we attain the following numbers: v¢ (1.5) = 0, v¢ (0.75) = 2, v¢ (0.5) = 3, v¢ (-0.25) = 4 which satisfy diminishing marginal utility of wealth. Notice that these numbers fulfill the first order condition above, i.e.:
The question now turns to u. As u is more risk-averse that v, then u = T(v) where T is a concave function. Thereby, forcing u to hold the portfolio a v, we have:
But as T¢ is concave, then it perfectly legitimate to assign the following numbers T¢ (0) = 1, T¢ (2) = 1, T¢ (3) = 10 and T¢ (4) = 10, thus:
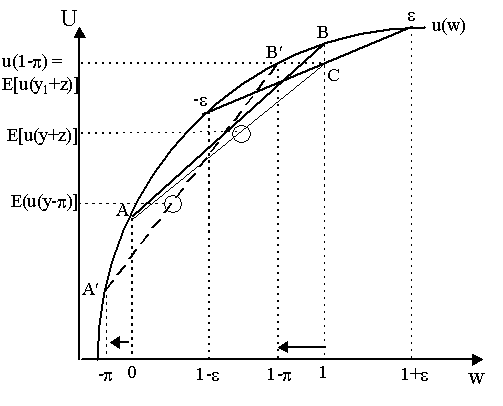
This is the slope of the expected marginal utility function of agent u forced to hold the portfolio of agent v. As the slope of u's marginal utility function at a v is positive, then this implies that his own optimal allocation a u is at a higher level. Thus, a u > a v. However, we posited that u was more risk-averse that v. Thus, from this example, it does not follow that if u is more risk-averse than v, then a u £ a v; rather, a more risk-averse agent can take a less risky position. What exactly is going on in this counterexample? With perfectly legitimate values for V and T, this example contradicts the Arrow-Pratt hypothesis and has more risk-averse agents choosing the riskier position. Notice that if a = 0, then we have merely the risk of y to contend with and the extra risk of random variable z is avoided.; if a = 1, then we take the full risk of x. So the question that imposes itself now is the following: given that the agent cannot avoid the risk of y, how much is he willing to pay to avoid the additional risk of adding z to that? In other words, we want to compute the risk premium of the extra risk of z. To understand the essence of the problem, examine the somewhat cluttered Figure 7. Suppose y is an asset which pays y1 = 1 or y2 = 0, each with some probability (p, 1-p). In Figure 7, the risky asset y is represented by the chord connecting points A and B on the utility curve, and E[u(y)] is expected utility of asset y. Suppose now that we add a little bit more of risk as we did when we added z before to y to obtain x. However, let us have it that y2 = 0 remains the same, but that y1 = 1 now has a little extra noise, thus let us only add z1 = e and z2 = -e to y1 alone. Assume z1 has probability q = 0.5 and z2 has probability (1-q) = 0.5 so that E(z) = qz1 + (1-q)z2 = (0.5)e + (0.5)(-e ) = 0. As we see in Figure 7, the extra risk z makes y1 + z range from 1+e to 1-e while y2 remains constant. In other words, our payoffs when we add the extra variable z to our existing random variable y are now y1 + z1 = 1+e , y1 + z2 = 1-e and y2 = 0. The extra randomness is represented by the chord connecting points e and -e in Figure 7. Thus, the expected utility of the whole combination of y+z is now:
which is shown heuristically in Figure 7 as a point on the chord connecting A and C.
What is the risk premium to get rid of the extra risk z? The Arrow-Pratt risk-premium is computed now using the chord (-e , e). Recall that E(z) = 0, thus the expected utility of y1 + z alone is shown in Figure 7 as E[u(y1+z)] which is obtained from point C on the chord (-e , e ). In order to get rid of the extra risk z, the agent would pay a premium p that yielded the "certainty-equivalent" allocation B¢ which thus results in (1-p ) and yields the same "certain" utility u(1-p ) as the old expected utility E[u(y1 + z)]. Thus, paying premium p , we move to point B¢ . However, because y1 is only one state of a risky asset, thus we do not obtain (1-p ) with "certainty", but rather (1-p ) becomes merely one of the possible payoffs. Our analysis does not end with this, then. A premium is a premium, and it will be paid before one knows whether y1 or y2 has realized itself. Consequently, we must also reduce y2 by the amount of the premium to -p . This is point A¢ . Thus, by paying the premium p , we have changed the returns in both cases y1 and y2 from 1 and 0 to 1-p and -p respectively, thus our chord AB representing risky asset y now moves to A¢ B¢ to represent risky asset minus premium, y - p , in Figure 7. Notice that expected utility is now reduced from uncertain E[u(y+z)] to uncertain E[u(y-p)]. The idea of the Arrow-Pratt measure was that it was a local measure and not a global one. As the premium paid to get rid of z affects payoffs elsewhere, then the shape of the utility curve elsewhere (i.e. around A and A¢ ) begins to matter because the impact of the risks are now spread over two states. In other words, the measure of risk-aversion should not be exclusively concentrated around B but one should also take into account the curvature around A. In short, we want a measure of average risk-aversion. Algebraically, the original expected utility E[u(y+z)], we had
so taking a Taylor expansion:
where o is a order of magnitude denoting the negligibility of the remainder. In contrast, once the premium is paid to get rid of z we have:
Thus, as E[u(y+z)] = E[u(y-p )] so that the premium is calculated to equate the expected utility of the risky situation y+z and the expected utility of the second y-p (which is not certainty-equivalent because y is not riskless!), then:
which solving for p yields:
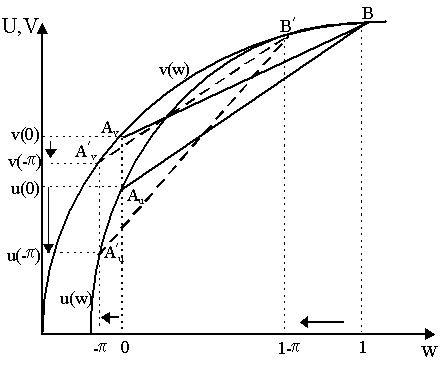
or:
thus the risk premium is calculated using the measure of risk aversion around y1, -u¢ ¢ (y1)/u¢ (y1) and the measure of risk-aversion around y2, -u¢ ¢ (y2)/u¢ (y2), thus we compute the premium from average risk-aversion. To understand why we obtained the paradoxical result in Ross that the less risk-averse agent pays a higher premium than the more risk-averse agent, we can appeal to (imperfectly drawn) Figure 8. Here we have two individuals u and v with utility functions which are identical around 1 but different around 0 - specifically, assume that u has a more concave utility function than v around 0 - thus agent u is more risk-averse (around 0 and thus on average) than agent v. We originally start with y which yields the chord AvB for agent v and AuB for agent u. Again, we presume we go through the same exercise as before in Figure 7 where we have a chord representing z, etc., etc. so that following the same story, we get rid of z by swinging the chord from AvB to Av¢ B¢ and AuB to AuB¢ . (notice that the upper part of the chord, B and B¢ remain the same for both agents as they have the same utility functions at higher levels of wealth). The important point to note in Figure 8 is that as the upper part of the utility curves are the same, then they would, ceteris paribus, pay the same premium p to get rid of z and thus for both agents the lower return would decline from 0 to 0-p . In paying this premium, agent u's utility around here falls from u(0) to u(-p ) and v's utility falls from v(0) to v(-p ). Thus, as we see in Figure 8, in paying the same premium, p , the reduction in utility of agent u around Au, Au¢ is more than the reduction in utility of agent v around Av, Av¢ . This means that in terms of utility lost, the cost of paying p is greater for agent u than it is for agent v. Notice that the loss in utility around 1 would be the same but the loss in utility around 0 would be heavier on u. Consequently, if we allowed them to choose their optimal risk premia rather than imposing it, then u would pay less than agent v to get rid of z. Thus, the individual with the steeper slope at 0 would want to pay less of a premium to avoid the same risk. But recall that u was more risk-averse than v. Thus, the more risk-averse individual u pays a smaller premium than the less risk-averse individual v for the same risk. The paradox of a u > a v we obtained in the Ross counterexample stems from something like this.
In sum, what Ross (1981) has illustrated is that the risk-premium is not a good measure of risk-aversion because we are not taking the "global" behavior of the utility function. The Arrow-Pratt risk-premium we paid to avoid the extra risk in state 1 is only a local risk-premium and is not a good measure of risk-aversion. In order to compensate for this, Stephen Ross (1981) suggested a stronger risk-aversion measurement (SRAM) that takes these global differences into account. This is defined as follows:
Another way of saying this is that infw u¢ ¢ (w)/v¢ ¢ (w) ³ supw u¢ (w)/v¢ (w¢ ). Note that there are two different wealth levels at which we compute the ratio of first and second derivatives, w¢ and w. Thus, if w = w¢ , then we have the old Arrow-Pratt measure of risk-aversion and thus this inequality can be written -u¢ ¢ (w)/u¢ (w) ³ -v¢ ¢ (w)/v¢ (w) so agent u is more risk-averse than agent v in the Arrow-Pratt sense. Thus, SRAM implies Arrow-Pratt, but Arrow-Pratt does not imply SRAM.
Proof: We go (1)Þ (2) Þ (3) Þ (1). (1) Þ (2): Let l > 0 and G(w) = v(w) - l u(w). Then G¢ (w) = v¢ (w) - l u¢ (w). Thus, l = G¢ (w)/u¢ (w) = v¢ (w)/u¢ (w) - l . By (1), v¢ (w)/u¢ (w) - l £ 0 and as u¢ (w) > 0, then G¢ (w) £ 0. Differentiating again, G¢ ¢ (w)/u¢ ¢ (w) = v¢ ¢ (w)/u¢ ¢ (w) - l . By (1), v¢ (w)/u¢ (w) - l ³ 0 but u¢ ¢ (w) < 0, thus G¢ ¢ (w) £ 0. Thus, G(w) is a decreasing concave function. (2)Þ (3) By definition, v(w-p v) = E[v(w+z)] = E[l u(w+z) + G(w+z)] by (2). Consequently, by Jensen's inequality, E[l u(w+z) + G(w+z)] £ l E[u(w+z)] + E[G(w+z)]. Now, as E[u(w+z)] = u(w-p u) by definition and G is concave, then using our inequalities:
but by definition l u(w-p u) + G(w-p u) = v(w - p u), thus:
or, as v is a concave utility function, the it must be that p u £ p v. (3) Þ (1): Note that maxp E[u(w-p u)] implies the following conditions for a maximum
where the second order condition implies, recalling u is concave, that:
To analyze this, let E[u(w-p u)] = pE[u(w1-p u)] + (1-p)E[u(w2 -p u)]. Without loss of generality, let us presume that there is an extra "noise" term attached to w1 but not to w2, which pays +e and -e with equal probability so E(e ) = 0. E[u(w-p u)] = p[0.5u(w1+e ) + 0.5u(w1-e )] + (1-p)u(w2). Now, let us normalize the optimal premium so that p u = 0 when e = 0. Thus, in this case, when e = 0, then E[u¢ (w-p u)] = pu¢ (w1) + (1-p)u¢ (w2) and E[u¢ ¢ (w-p u)] = pu¢ ¢ (w1) at the optimum premium, p u =0. Thus, the second order conditions imply:
Notice that this expression is identical to ¶ 2p u(e )/de
2|e =0, so p u
is a convex function of e centered at 0. Now, if p u > p u, then
this implies that at e = 0, p u(e ) is more "convex" than p v(e ), or:
which can be rewritten:
for every w1, w2. Letting p ® 0, we see that this implies:
for every w1, w2. This is Ross' condition for SRAM. Thus (3) Þ (1). § To understand the implications of Ross's measure, let us turn to portfolio problem again. Let us again have our standard structure with y being a risky asset and z the extra "noise" on y which is independent of y and E(z|y) > 0. Normalizing wealth w = 1, then expected utility of agent u is E[u(y + a uz)] and expected utility of agent v is E[v(y + a vz)] where a u and a v are is the optimal proportion of wealth held in the riskier asset. Thus the optimization problem for agent u is to choose a to maximize expected utility. As a consequence, we obtain the first order condition that:
Let us force agent u to hold agent v's optimal portfolio, then expected marginal utility of agent u is, in this case, E[u¢ (y+a vz)·z]. Suppose that u is more risk-averse than v in the sense of Ross: in this case, we know that u(y+a z) = l v(y+a z) + G(y+a z) as implied by Ross's measure, where G is a decreasing concave function. Then when forcing agent u to hold a v, we have:
or, as E[v¢ (y+a vz)·z] = 0 by v's first order condition, then this reduces to:
Now, let q (z) = G¢ (y+a vz). As G is a decreasing function, then q (z) < 0. As G is concave, then q ¢ (z) = G¢ ¢ (y+a vz)a v < 0. Now, assuming z is independent of y, E[q (z)·z] = E[E(q (z))·z|y]] = E[cov(q (z), z | y] + E[q (z)|y]·E(z|y)]. Now as E(z|y) > 0 and q ¢ (z) < 0, then E[cov(q (z), z) | y] + E[q (z)|y]·E(z|y)] £ E[cov(q (z), z | y]. Consequently, by concavity, E[cov(q (z), z | y] < 0. Thus:
The result that E[u¢ (y+a vz)·z] < 0, implies that the expected utility function of agent u is declining when he is forced to hold a v. Thus, following our earlier logic, this implies necessarily that a v ³ a u, i.e. the more risk-averse the agent, the less he invests in the risky asset. Thus, Ross's stronger measure of risk-aversion seems to give the right result. A final thing needs to be mentioned at this point. Although we have shown that a more risk-averse agent holds a less risky position, it does not follow that if someone holds a less risky position implies they are more risk-averse. That the reverse does not hold was shown by Machina and Neilson (1987) when comparing a risk-averse u and a risk-loving v. However, they argued that if we restrict our comparison to risk-averse agents or restrict it entirely to risk-lovers, so that we do not have cross-comparisons, then indeed the reverse holds. Finally, one thing we have not touched upon has been measures of risk-aversion in a multi-variable context. This was first broached by Menachem Yaari (1969) and is examined in the section on state-preference, within which it seems to fit a bit more appropriately.
K.J. Arrow (1965) Aspects of the Theory of Risk-Bearing. Helsinki: Yrjö Hahnsson Foundation. M. Friedman and L.P. Savage (1948) "The Utility Analysis of Choices involving Risk", Journal of Political Economy, Vol. 56, p.279-304. J. Hicks (1962) "Liquidity", Economic Journal, Vol. 72, p.787-802. M.J. Machina and W.S. Neilson (1987) "The Ross Characterization of Risk Aversion: Strengthening and extension", Econometrica, Vol. 55 (5), p.1139-50. H. Markowitz (1952) "The Utility of Wealth", Journal of Political Economy, Vol. 60, p.151-8. H. Markowitz (1952) "Portfolio Selection", Journal of Finance, Vol. 7, p.77-91. H. Markowitz (1958) Portfolio Selection: Efficient diversification of investment. New Haven, Conn: Yale University Press. J.W. Pratt (1964) "Risk Aversion in the Small and in the Large", Econometrica, Vol. 32, p.122-36. S.A. Ross (1981) "Some Stronger Measures of Risk Aversion in the Small and in the Large with Applications", Econometrica, Vol. 49 (3), p.621-39. J. Tobin (1958) "Liquidity Preference as a Behavior toward Risk", Review of Economic Studies, Vol. 25, p.65-86.
|

All rights reserved, Gonçalo L. Fonseca