Contents (A) First and Second Order Stochastic Dominance (A) First and Second Order Stochastic Dominance When is a particular random prospect "better" than another random prospect? As von Neumann-Morgenstern argue, the answer is readily available for a single person: the expected utility of the first prospect is greater than the second. However, for most economic applications this does not really suffice as we cannot observe "utility". Might there be a way of comparing the random prospects by the observable properties of the different random prospects? Perhaps. For uncertainty with univariate payoffs (i.e. "wealth" or "money" payoffs), a random variable can be described via a cumulative distribution function. This will contain effectively all of the relevant information about the "objective" properties of the random variable. Thus, comparison between different random prospects can be approached by examining their associated cumulative distribution functions. Suppose over a compact support [a, b], we have two random variables, one of which is associated with cumulative distribution F and another with cumulative distribution G. When can we say that F is "better" than G for a particular agent? Expected utility be constructed as an integral over this support via the cumulative distribution function. Specifically, expected utility from the random variable with cumulative distribution F can be written U(F) = ò ab u(x) dF(x) and expected utility of the random variable with cumulative distribution G is U(G) = ò ab u(x) dG(x). Note that U(·) is the von Neumann-Morgenstern utility function whereas u(·) is the associated elementary utility function. If U(F) ³ U(G), then F is preferred to G by the relevant agent. If every reasonable agent prefers prospect F to prospect G, then we can say that, on the whole, F dominates G. We ought to make this more precise. Letting U0 be the set of all elementary utility functions u: X ® R that are monotonically increasing, then let us define the following:
Thus, a random variable with distribution F "dominates" another random variable with distribution G if everybody who has a utility function which is monotonically increasing thinks F is better than G. However, returning to the empirical problem, where utility is not observable, when can we say that prospect F dominates G? In other words, by only observing the properties of the cumulative distribution functions, can we say whether F dominates G or not? In general, no; in certain cases, perhaps. One ought to expect, for instance, that just about everyone will consider a prospect which has a lot of probability mass skewed towards higher returns to be better than a prospect which has a lot of probability mass skewed towards low returns. If such is the case, then we have what is called "first order stochastic dominance". This is defined as follows:
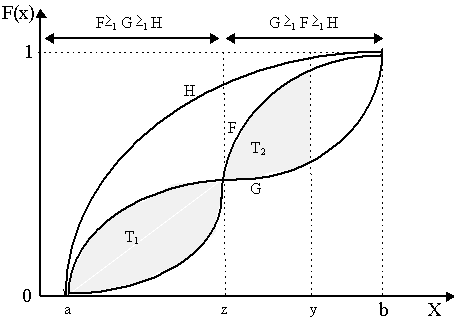
We can see this more or less in Figure 1 below when comparing the cumulative distribution function H with either F or G. Specifically, note that for any x Î [a, b], F(x) £ H(x) and G(x) £ H(x) as H lies uniformly above F or G. Considering any x Î [a, b], then we see immediately that there is more "area" under the curve between a and x then there is under the F or G curve between a and x. Thus, there is a greater probability mass under H(x) than F(x) or G(x) for any x Î [a, b], i.e. the probability that any t is less than x under H is greater than the probability that any t is less than x under F or G. Thus both F and G dominate H. Is this consistent with the von Neumann-Morgenstern theory? In other words, can we say that if F is preferred to G according to the first order stochastic dominance criteria, then necessarily that implies that expected utility of F is greater than expected utility of G for any agent with a monotonically increasing utility function? Indeed, this is so:
Proof: This is an if and only if statement, thus we must prove it both ways. For the "if" part, suppose F ³ 1 G holds, i.e. F(x) £ G(x) for all x Î [a, b] or [F(x) - G(x)] £ 0 for all x. Now, for any u Î U0, consider the integral ò ab u(x)[dF(x) - dG(x)]. Then integrating by parts:
as [F(x) - G(x)]ab = 0 and u¢ (x) > 0 thus, then the inequality follows from [F(x) - G(x)] £ 0 for all x. As this holds true for any u Î U0, then ò ab u(x)dF(x) ³ ò ab u(x)dG(x) for all u Î U0. Conversely, for the "only if" part, suppose it is not the case that F(x) £ G(x) for all x Î [a, b]. Then, there is an x0 such that F(x0) > G(x0). By right continuity, there is a neighborhood Ne (x0) such that G(x) < F(x) for all x Î Ne (x). Let u Î U0 be such that it takes on constant values outside Ne (x0) but increasing within Ne (x0), i.e. u¢ (x) > 0 for x Î Ne (x0) and u¢ (x) = 0 for x Ï Ne (x0). Thus, ò ab u¢ (x)[F(x) - G(x)dx = ò N(x) u¢ (x)[F(x) - G(x)]dx > 0 or -ò N(x) u¢ (x)[F(x) - G(x)]dx < 0. But, we know from integrating by parts that:
But as the right hand side is negative, then ò ab u(x)dF(x) < ò ab u(x)dG(x), thus it is not true that F ³ 1 G. Thus, F³ 1G Þ F(x) £ G(x) for all x Î [a, b].§
The first order stochastic dominance criteria seems apt in comparing H with either F or G in Figure 1. However, note that this criteria fails when comparing the cumulative distribution functions F and G with each other. Obviously, neither F nor G are uniformly above each other thus it neither F dominates G nor G dominates F. In particular, note that below point z, F(x) £ G(x), whereas above point z, F(x) ³ G(x), or [1-G(x)] £ [1-F(x)]. As we cannot compare F and G according to the first order stochastic dominance criteria, then ³ 1 is only a partial ordering on the space of cumulative distribution functions. The purpose of the first order stochastic dominance is to enable us to order (if only partially) distributions according to their return: in other words, F >1 H implies that F is unambiguously "better" than H because it deposits the bulk of its probability mass at a higher return, and thus will have a higher expected return (and utility). But, as we see in Figure 1, we cannot compare F and G by this criteria. If z is the mean, then F and G have the same expected return. However, in Figure 1, it also seems as if the probability mass of F is "less dispersed" than G, and thus, in a sense, ought to be considered "less risky". An alternative criteria, then, would be argue that a particular distribution is better than another (at least for risk-averse people) if it has unambiguously "lower" risk. This is the purpose of the second order stochastic dominance criteria. Second order stochastic dominance criteria helps us rank distributions according to relative riskiness in terms of the spread of the probability mass of the cumulative density functions. In order to move in that direction, let us define T(x) as the area between the two curves F and G in [a, x], specifically T(x) = ò ax[G(t) - F(t)]dt. In Figure 1, we can notice that everywhere below z, G is above F, thus the area in between the curves below z is T1 = ò az[G(t) - F(t)]dt > 0. However, above z, G is below F, thus (negative of) the area between the curves above z is ò zb[G(t) - F(t)]dt < 0. But notice that T(x) is cumulative, i.e. T(x) = ò az[G(t) - F(t)]dt + ò zx[G(t) - F(t)]dt for all x Î [a, b], thus we add up the areas where G is above F and subtract from it the areas where G is below F (note: we can allow G and F to rise above and dip below each other several times over the range). Thus, in Figure 1, T(y) = ò ay[G(t) - F(t)]dt is the sum of the areas T1 and T2 where, notice, T1 > 0 and T2 < 0. If T(x) ³ 0 for all x Î [a, b], then the cumulative area where G is above F is greater than the area where F is above G, i.e. the probability mass of G is more spread out than the probability mass of F - which we may say implies that G is "riskier" than F - which is what we see in Figure 1. Conversely, if T(x) £ 0 for all x Î [a, b], then the mass of F is more spread out than G. [However, one must be careful here. Spread is not the same as "variance". There are many situations where for two distributions, F and G, the distribution F has the same mean and less variance than G and yet also yields lower expected utility than G. To visualize such a situation, imagine a random prospect with three returns (x1, x2, x3), where x1 < x2 < x3, where x2 happens to be the mean. We can decrease x1 a little and increase x3 a little so that we retain the same mean, and we can even reduce the probability of either x1 or x3 occurring (and thereby increase the probability of x2) so that variance is reduced. Yet with a concave utility function, it is still entirely likely that expected utility is lowered as a consequence. Alternatively, imagine two skewed distributions with the same mean, albeit with the one with higher variance being skewed upwards and thus potentially preferable. Reduction in variance, keeping mean constant, does not necessarily mean a rise in expected utility (there are cases when a reduction in variance does increase expected utility unambiguously, but we must then restrict the kinds of utility functions we can accept, e.g. quadratic utility, or the distributions of returns must be completely describable by mean and variance).] We want to "rank" distributions F and G according to whether T(x) is positive or negative over the entire range. Thus, we now define the following:
Notice in Figure 1 that it is quite probable that F ³ 2 G by this criterion, thus F dominates G according to second order stochastic dominance. Notice also that if T(x) compares H with F or G, then it is indeed true that F ³ 2 H and G ³ 2 H. Thus, first order stochastic dominance implies second order stochastic dominance, but not vice-versa.
Proof: Suppose F ³ 2 G and consider ò ab u(x)[G(x) - F(x)]dx. Integrating by parts:
as [G(x) - F(x)]ab = 0, then:
integrating the right-hand side by parts again:
or, noticing that T(x) = ò ax [G(t) - F(t)]dt, then:
Now, as [T(x)]ab = 0, then this reduces to:
where the inequality follows from the fact that u¢ ¢ (x) £ 0 by concavity of u Î U1 and T(x) ³ 0 by the assumption of second order stochastic dominance. Thus:
Conversely, for the "only if" part, suppose it is not the case that F ³ 2 G. Then there is an x0 Î [a, b] such that T(x0) < 0. By continuity, define Ne (x0) as the neighborhood around x0 where T(x) < 0 for all x Î Ne (x). Now, consider a u which is linear on [a, x0-e ] and on [x0+e ] and concave on Ne (x0). Recall from the earlier proof that:
thus as u¢ ¢ (x) = 0 for all x Ï Ne (x0) and [T(x)]ab = 0, then:
As u¢ ¢ (x) £ 0 for x Î Ne (x) and T(x) < 0 by hypothesis, then ò ab u(x)[G(x) - F(x)]dx > 0 as a result, or not ò ab u(x)F(x)dx > ò ab u(x)G(x)dx. Thus, ò ab u(x)dF(x) > ò abu(x)dG(x) implies F ³ 2 G.§ (B) The Characterization of Increasing Risk Let us now turn to the definition of "riskiness". A series of similar definitions was pursued independently by J. Hadar and W. Russell (1969), G. Hanoch and H. Levy (1969) and, perhaps most famously, Michael Rothschild and Joseph E. Stiglitz (1970, 1971). The first definition we would like apply is almost behavioral in its implications. Namely, we can say that a distribution G is "riskier" than a distribution F if risk-averters prefer F to G. A risk-averter, recall, has a concave utility function, u Î U1. Thus, we would like to use the following definition (m F is the mean of distribution F):
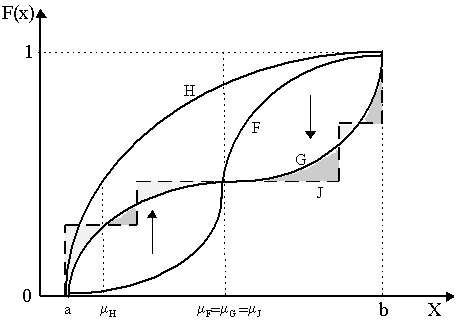
In other words, a distribution G is riskier than F if, controlling for the same expected value (m F = m G), the expected utility of F is greater than the expected utility of G of risk-averse agents (u Î U1 implies u concave). Another notion of higher risk is the Rothschild and Stiglitz (1970) idea of a mean-preserving increase in spread (MPIS). This means that given a distribution F, we construct another distribution G by "increasing" the spread, i.e. moving mass away from the center of the distribution to its tails in a manner such that the mean remains the same. This is depicted in Figure 2. Moving from F to G, we have "fattened" the tails but maintained the same mean m F and m G, thus a move from F to G is a MPIS. Of course, in Figure 2, H is not a mean-preserving increase in spread on either F nor G as the mean of H (m H) is below that of G and F. Notice that for distribution J, a move from F to J is a MPIS as spread increases and m J = m F, but a move from G to J is not MPIS because even though the mean is preserved (m J = m G), the spread has not increased for all x. Thus, a MPIS move from any distribution to another implies there is a single-crossing property between the distributions, i.e. they cross only once - and that is at the mean. In Figure 2, J crosses F only once, but it crosses G at several points.
The MPIS of Rothschild-Stiglitz (1970) implies another definition of riskiness, namely F is less risky that G if G is generated by an mean-preserving increase in spread on F, i.e.
We actually ought to verify that T(b) = 0 implies equality of mean. Specifically: T(b) = ò ab[G(x) - F(x)]dx = 0 Û m F = m G Proof: Note that if T(b) = 0, then ò ab[G(x) - F(x)dx = 0. Or, integrating by parts:
as m F = ò abx¦ (x)dx and m G = ò abxg(x)dx and ¦ = F¢ and g = G¢ are probability distributions. The converse applies in reverse.§ Thus, the first part of the (R.2) definition of riskiness, T(b) = 0, implies the preservation of mean while the second part, T(y) ³ 0, refers to the increase in spread. Notice that we do not make use of "utility" in this definition thus it may seem "less" behavioral than the previous (R.1) definition. However, they lead to the same result, namely:
Proof: The proof is the same as the proof of second-order stochastic dominance in the previous section, only now we add T(b) = 0 in addendum.§ Notice the implication that the MPIS criteria effectively implies second order stochastic dominance and, if we confine our attention to distributions with the same mean, second order stochastic dominance implies MPIS. This is evident from Figure 2: by the MPIS criteria, we cannot compare distributions G and J, but we can by the second-order stochastic dominance criteria. Specifically, note that T(b) = ò ab[J(x) - G(x)]dx is the difference between the lightly-shaded areas (where J lies above G) and the darkly-shaded areas (where G lies above J). Thus, if the sum of the lightly-shaded areas are greater than the sum of the darkly shaded areas, then T(b) > 0 and J is said to dominate G by second-order stochastic dominance. Thus, by imposing T(b) = 0, we are omitting comparisons along these lines - and thus we obtain the single-crossing property and our definition of MPIS. Finally, we provide the third definition of riskiness, also due to Rothschild-Stiglitz
Thus, we construct random variable y from x by adding an extra degree of riskiness or "noise", e , to the outcomes of x. In this case, y is unambiguously riskier than e . One can visualize that if F is the distribution associated with random variable x and G is the distribution of random variable y, then G is a mean-preserving increase in spread on F. Thus, as Rothschild and Stiglitz (1970) prove (although the proof stretches back to Hardy, Littlewood and Polya in the 1930s), the three definitions of riskiness are equivalent. In short, increasing risk is what risk-averters dislike (R.1), the movement of probability mass from center of a distribution to its tails (definition R.2) and the adding of noise to a random variable (definition R.3). (C) Application: Portfolio Allocation With the definition of riskiness in hand, let us consider the old portfolio allocation problem where agents choose their optimal portfolio allocation a * between a riskless asset with no return and a risky asset with return x and E(x) > 0. Recall that we showed that in such a case, more risk-averse agents will choose a smaller a *. Consequently, we would like to hypothesize that if the risky asset became riskier by a mean-preserving increase in spread, then a risk-averse agent would move away from it, i.e. the optimal portfolio allocation a * would decline. Unfortunately, as we shall see, that is not necessarily true. Increases in risk may decrease expected utility, but that does not mean that a * declines. To see this, consider the following. Normalizing initial wealth w = 1, then the agent's consumer's optimal portfolio decision a * is made by maximizing expected utility E[u(1+a x)] where x is the return on the risky asset. The first order conditions for a maximum imply:
or assuming the risky asset can take a continuum of values in a closed interval [a, b] Ì R and is characterized by the cumulative distribution F, then this becomes
Now, let us define:
where r Î [0, 1]. Thus, H(·, r) generates a family of distributions where, if r = 0, then H(·, r) = F(·) and if r = 1, then H(·, r) = G(·). Let G be "more risky" than F, in other words, G is a mean-preserving increase in spread over F. Then the family generated by H(·, r) as r goes from 0 to 1 is a linear path or sequence of riskier (MPIS) distributions from F to G. Consider now the following:
Proof: For any distribution H(x, r) we have the first order condition:
where, again, if r = 0, then H(x, r) = F(x) and if r = 1, then H(x, r) = G(x). As different a are generated for different distributions, we see, then, that a will be some function of r. To make our notation compact, let u(1-a x) = u(a , x) and thus ua(a , x) = u¢ (1-a x)·x and uaa (a , x) = u¢ ¢ (1-a x)·x2. Now, totally differentiating the first order condition at a *:
or:
Now, Hr(x, r) = dH(x, r)/dr = -dF(x) + dG(x) or simply:
As a result:
Now the denominator is clear enough: as uaa < 0 by the concavity of u, then the denominator is negative. The numerator is more complicated. We know also that ua > 0, but we do not know the implications of d[G(x) - F(x)] on the sign. So, integrating the (negative of the) numerator by parts, we obtain:
where as the first term [G(x)-F(x)]|ab = 0, then:
The term ua x(a *, x) is the derivative of marginal utility with respect to x. Now, integrating the right-hand side by parts:
or, as (ò ax[G(t) - F(t)]dt)|ab = T(b) = 0 by the assumption of MPIS and ò ax[G(t) - F(t)]dt] = T(x), then this becomes:
As G(x) is an MPIS on F(x), then we know that T(x) > 0. But what about uaxx? If we assume that marginal utility is concave in x, then uaxx < 0. If this is true, then ò ab ua(a *, x)d[G(x) - F(x)] < 0 and so the numerator is positive, so, in conclusion, term da */dr > 0, i.e. an increase in risk defined via MPIS will lead to a reduction in investment in the risky asset.§ The question that imposes itself here, of course, is what economically-intuitive conditions on behavior guarantee that marginal utility is concave in x? None, really. Neither risk aversion, nor increasing/decreasing absolute risk aversion, nor much of anything else yields us uaxx < 0. Taking our explicit form, we can see that:
we are certain that the last part of the last term 2u¢ ¢ (w+a wx)a x2 is negative, but we have no assumptions on the third derivative of the utility function (u¢ ¢ ¢ ) we need to derive the concavity of marginal utility. To see that assuming decreasing absolute risk aversion (DARA) does not help us, recall that DARA says d[-u¢ ¢ (w)/u¢ (w)]/dw < 0 or:
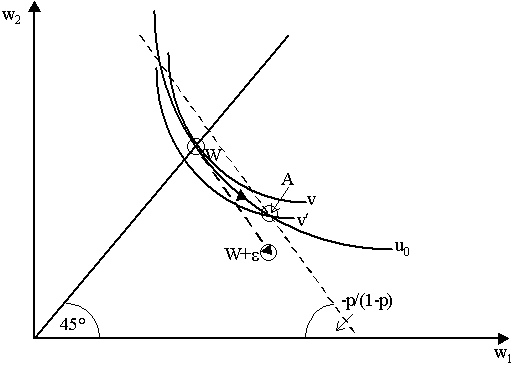
where we see the third derivative u¢ ¢ ¢ (w). Now, the denominator is positive, thus the numerator must be negative, which implies that u¢ ¢ ¢ (w) > 0. This is great, but that does not help us to find the sign of uaxx. Why? Because uaxx = u¢ ¢ ¢ (w+a wx)a 2w3x + 2u¢ ¢ (w+a wx)a x2, but the rightmost term is negative; thus having found that u¢ ¢ ¢ (w) > 0 via DARA only tells us we are adding a positive to a negative. That is not enough to tell whether uaxx is positive or negative. Might increasing absolute risk-aversion help? Not quite. All that IARA implies is that u¢ ¢ (w)2 > u¢ (w)u¢ ¢ ¢ (w). As u¢ ¢ (w)2 > 0 and u¢ (w) > 0, then u¢ ¢ ¢ (w) can now be either positive or negative to fulfill IARA. Thus we now can't get u¢ ¢ ¢ and thus have even less hope of establishing the sign of uaxx. In sum, economic reasoning is of little assistance. We simply have to make an exogenous assumption that ua is concave in x. (D) Alternative Measures of Increasing Risk An alternative characterization of increasing risk was provided by Peter Diamond and Joseph E. Stiglitz (1974) in the form of mean utility-preserving increase in spread (MUPIS). This can be visualized by appealing to the two-state diagram in Figure 3. Suppose we begin at certain allocation W. Notice that we have two indifference curves passing through W: u0 and v where, notice, v is more convex than u, thus v is more risk-averse. Now, if we attempted a mean-preserving increase in risk (MPIS) that would involve a straight-line movement from W to a point such as W+e and this movement would have a slope of -p/(1-p). However, instead of doing this, let us instead move to a point such as A. The movement from W to A is an increase in risk as we are moving away from the certainty line, but it is not a "mean-preserving" increase because the movement from W to A is not at angle -p/(1-p). However, notice that at A, the utility of the more risk-averse agent is lower (at v¢ ) but that of the less risk-averse agent remains the same at A as it was at W, i.e. it stays at u0.
However, from the point of view of agent u0, the movement from W to A is a mean utility preserving increase in spread, or a MUPIS. Why? It is obvious that expected utility is the same, but expected return is higher, as we can see by the intersection of the -p/(1-p) curve at point A. Thus, it is as if we using a higher expected return to compensate agent u0 for the loss in utility that arises from the increase in risk - so his expected utility remains the same. Of course, from the perspective of agent v, the movement from W to A is a mean-utility decreasing increase in spread. The basic idea behind Diamond and Stiglitz (1974) is to exploit this notion. Now if w is a random variable, we know that as a consequence, u(w) is a random variable as well. If F(x) is the distribution of random variable w, then, correspondingly, we can posit F (u) as the related distribution of random variable u(w). Consequently, we can define a MUPIS by using the definition of MPIS but only replacing distributions F(x) and G(x) with analogous F (u) and G (u). It is easy to note that F(x) = F (u(x)), where, note, F = F ° u, thus F is some transformation of u which makes it equal to the distribution of the random variable, F. As x Î [0, 1], then we can normalize u via some projection of von Neumann-Morgenstern utility so that u Î (0, 1), thus x and u are defined over the same interval [a, b]. Thus we can now define a mean utility preserving increase in spread (MUPIS) as follows:
where we can immediately note the analogue with MPIS, thus G is riskier than F in the MUPIS sense. However, F = F ° u, then, by an appropriate change of variable technique, we can rewrite the MUPIS conditions as:
where u¢ (x) is marginal utility. Let us now turn to the mean utility decreasing increase in spread for the more risk-averse agent v. Letting v = T(u(x)) where T is concave because v is more risk-averse than u, then we know that agent v's change in expected utility can be written:
or, integrating the right-hand side by parts:
Or, as [G(x)-F(x)]|ab = 0, then this reduces to:
By now we should have learnt that whenever we are in a fix, we should integrate by parts again - and thus we do so:
Now, we know by condition (i) of MUPIS that [ò ay u¢ (t)[G(t)-F(t)]dt]|ab = 0, thus we are left with:
Now, T¢ ¢ (·) < 0 by concavity (from the greater risk-aversion of v), u¢ (x) by assumption so, finally, by condition (ii) of MUPIS, we know that [ò ax u¢ (t)(G(t)-F(t))dt] ³ 0. Thus the whole term is negative, i.e.
so a mean utility-preserving increase in spread for u leads to a mean utility-decreasing increase in spread for v. Diamond and Stiglitz (1974) use this relationship, in fact, to provide another definition of risk-aversion, i.e. v is more risk-averse than u if an increase in spread that maintains expected utility of u implies that the expected utility of v is lower.
P. Diamond and J.E. Stiglitz (1974) "Increases in Risk and in Risk Aversion", Journal of Economic Theory, Vol. 8, p.337-60. J. Hadar and W. Russell (1969) "Rules for Ordering Uncertain Prospects", American Economic Review, Vol. 59, p.25-34. G. Hanoch and H. Levy (1969) "The Efficiency Analysis of Choices involving Risk", Review of Economic Studies, Vol. 36, p.335-46. M. Rothschild and J.E. Stiglitz (1970) "Increasing Risk I: a definition", Journal of Economic Theory, Vol. 2 (3), p.225-43. M. Rothschild and J.E. Stiglitz (1971) "Increasing Risk II: its economic consequences", Journal of Economic Theory, Vol. 3 (1), p.66-84.
|

All rights reserved, Gonçalo L. Fonseca